
Speech Synthesis & Speech Recognition Using SAPI 5.1
To download the files associated with this article for Delphi 5, 6 and 7 click here, for Delphi XE7 click here and for Delphi 10.4.2 click here.
If you find this article useful then please consider making a donation. It will be appreciated however big or small it might be and will encourage Brian to continue researching and writing about interesting subjects in the future.
This article looks at adding support for speech capabilities to Microsoft Windows applications written in Delphi, using the Microsoft Speech API version 5.1 (SAPI 5.1). For an overview on the subject of speech technology please click here.
There is also coverage on using SAPI 4 to build speech-enabled applications. Information on using the SAPI 4 high level interfaces can be found by clicking here, whilst discussion of the low level interfaces can be found by clicking here.
SAPI 5.1 exposes most of the important interfaces, types and constants through a registered type library (SAPI 5.0 did not do this, making it difficult to use in Delphi without someone writing the equivalent of the JEDI import unit for SAPI 5). This means that you can access SAPI 5.1 functionality through late bound or early bound Automation. We will focus our attention on early bound Automation, which requires you to import the type library.
Choose Project | Import Type Library... and locate the type library described as Microsoft Speech Object Library (Version 5.1) in the list. Now ensure the Generate Component Wrapper checkbox is checked so the type library import unit will include component wrapper classes for each exposed Automation object. These components will go on the ActiveX page of the Component Palette by default, but you may wish to specify a more appropriate page, such as SAPI 5.1.
Now press Install... so the type library will be imported and the generated components will be installed onto the Component Palette (pressing Create Unit would also generate the type library import unit, but would require us to install it manually).
The generated import unit is called SpeechLib_TLB.pas and will be installed in a package. You can either select the default package offered (the Borland User Components package by default), choose to open a different package or even create a new one. When the package is compiled and installed you will get a whopping set of 19 new components on the SAPI 5.1 page of the Component Palette.
Each component is named after the primary interface it implements. So for example, the TSpVoice component implements the SpVoice interface. You can find abundant documentation on all these interfaces in the SAPI 5.1 SDK documentation.
Ready made SAPI 5.1 packages containing Automation components for Delphi 5, 6 and 7 can be found in appropriately named subdirectories under SAPI 5.1 in the accompanying files.
Note: if you are using Delphi 6 you will encounter a problem that is still present even with Update Pack 2 installed. The type library importer has a bug where the parameters to Automation events are incorrectly dispatched (they are sent in reverse order) meaning that all the Automation events operate incorrectly (if at all). You can avoid this by importing the type library in Delphi 5 or 7 and using the generated type library import unit in Delphi 6. A Delphi 6 compatible package is supplied with this article's files (it uses a Delphi 5 generated type library import unit).
Note: The Delphi 7 type library importer has been improved to produce more accurate Pascal representations of items in the type library than Delphi 5 did (and than Delphi 6 tried to). As a result of this, the event handlers will often have different parameter lists in the Delphi 7 imported type library. This means that the sample programs won't compile with Delphi 7 with the true Delphi 7 SAPI type library import unit.
If you wish, you can write late bound Automation that calls CreateOleObject to instantiate the Automation objects. In the case of the SpVoice interface, you would execute:
|
At its simplest level, all you need to do to get your program to speak is to use a TSpVoice Automation object and call the Speak method. A trivial application that does this can be found in the TextToSpeechSimple.dpr project in the files associated with this article. The code looks like this:
|
And there you have it: a speaking application. The call to Speak takes a number of parameters that we should examine:
|
When the program executes it lets you type in some text in a memo and a button renders it into the spoken word.
That's the simple example out of the way, but what can we achieve if we dig a little deeper and get our hands a little dirtier? The next project, which holds the answers to these questions, can be found as TextToSpeech.dpr in this article's files. You can see it running in the screenshot below; notice that as the text is spoken, the current sentence is italicised and the current word is displayed selected and also the phonemes spoken are written to a memo.
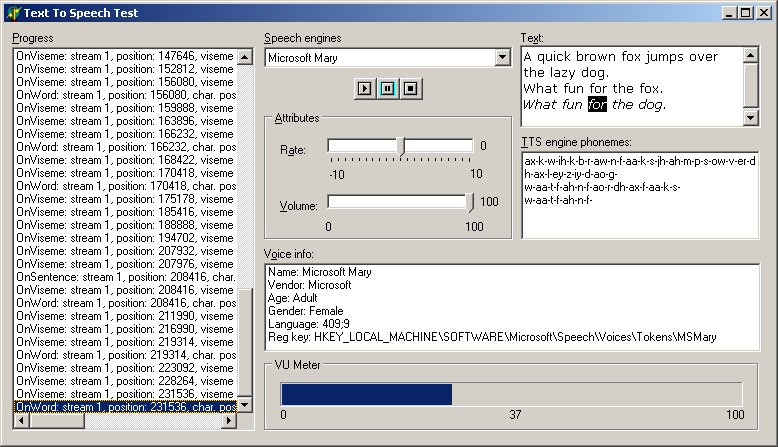
The following sections describe the important parts of the code from this project.
The first thing the program does is to add a list of all the available voices to the combobox and set the rate and volume track bar positions. The latter part of this is trivial as the voice rate and volume are always within predetermined ranges (the volume is in the range 0 to 100 and the rate is in the range -10 to 10).
|
The SpVoice object's GetVoices method returns a collection object that allows access to each voice as an ISpeechObjectToken. In this code, both parameters are passed as empty strings, but the first can be used to specify required parameters of the returned voices and the second for optional parameters. So a call to GetVoices('Gender = male', '') would return only male voices.
In order to keep track of the voices, these ISpeechObjectToken interfaces are added, along with a description, to the combobox's Items (the description in the Strings array and the interfaces in the Objects array).
Storing an interface reference in an object reference is possible as long as we remember exactly what we stored, and we don't make the mistake of accessing it as an object reference. Also, since the interface reference is stored using an inappropriate type, it is important to manually increment its reference count to stop it being destroyed when the RTL code decrements the reference count at the end of the method.
The OnDestroy event handler tidies up these descriptor objects by decrementing their reference counts, thereby allowing them to be destroyed.
|
When the user selects a different voice from the combobox, the OnChange event handler selects the new voice and displays the voice attributes (including the path in the Windows registry where the voice attributes are stored).
|
There are different calls to start speech and to continue paused speech, so a helper flag is employed to record whether pause has been pressed. This allows the play button to start a fresh speech stream as well as continue a paused speech stream. The text to speak is taken from a richedit control and is spoken asynchronously thanks to the SVSFlagsAsync flag being used.
|
There is another speech demo in the same directory in the project TextToSpeechReadWordDoc.dpr. As the name suggests, this sample reads out loud from a Word document. It uses Automation to control Microsoft Word (as well as the SAPI voice object).
|
The SpVoice object has a variety of events that fire during speech. Each block of speech starts with an OnStartStream event and ends with OnEndStream. OnStartStream identifies the speech stream, and all the other events pass the stream number to which they pertain. As each sentence is started an OnSentence event fires and there is also an OnWord event that triggers at the start of each spoken word.
Additionally (among others) an OnAudioLevel event allows a progress bar to be used as a VU meter for the spoken text. However it is important to note that for some events to fire you must set the EventInterests property accordingly; to receive the OnAudioLevel event you should set EventInterests to SVEAudioLevel or SVEAllEvents.
|
An OnViseme event is triggered for each recognised viseme (a portion of speech requiring the mouth to move into a visibly different position); there are 22 different visemes generated by English speech and these are based on the Disney 13 visemes (cartoons have less granularity and Disney animators discovered many years ago that only 13 cartoon mouth shapes are required to represent all English phonemes).
If you have some artistic flair and can draw a mouth in each position represented by the visemes you could use this event to provide a simple animated representation of speech.
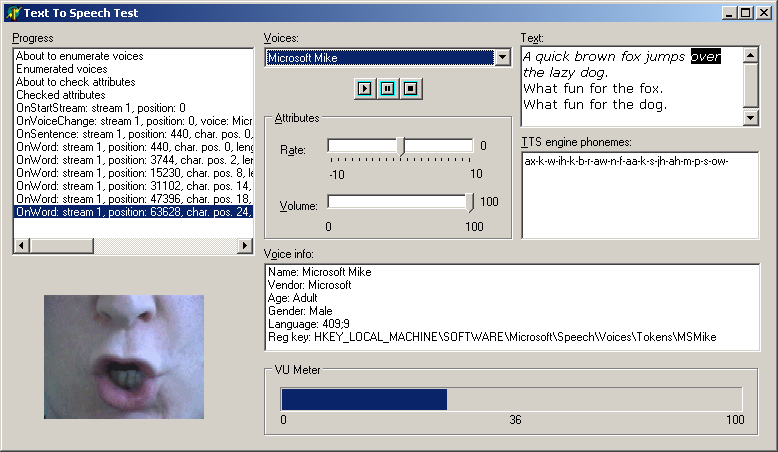
The SAPI 5.1 SDK comes with a C++ example called TTSApp, which displays an animated cartoon microphone whose mouth is drawn to represent each viseme. The microphone is made up from a number of separate images that can all be loaded into an image list. The additional demo program TextToSpeechAnimated.dpr makes use of these images to show how the effect can be achieved.
|
The OnViseme event gets the image list to draw on a paint box component and the image to draw is identified from a simple lookup table. There are 22 different visemes, but only 13 images (as in the Disney approach). Occasionally the code also draws narrowed or closed eyes, but whenever the silence viseme is received (at the start and end of each sentence) the default microphone (the first image in the image list) is drawn.
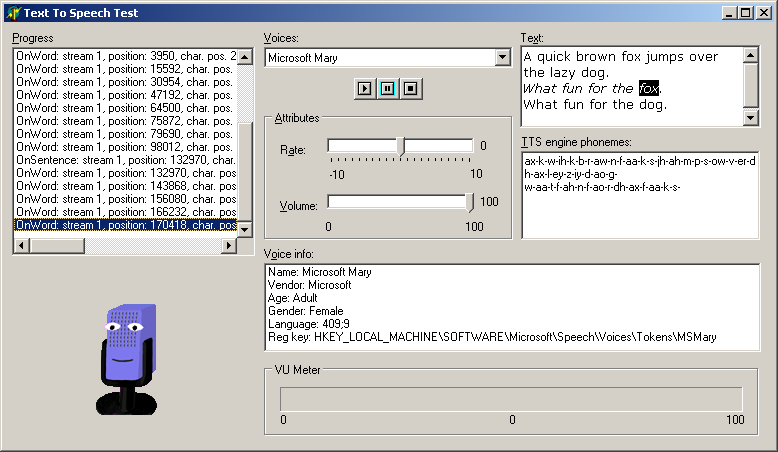
You can take this idea further if you need, by using images of a person's face saying each of the 22 visemes (for real people it seems to work best if you use 22 images, rather than 13). This way you can animate a real person's face in sync with the spoken text quite trivially.
We can use OnWord and OnSentence to highlight the currently spoken work or sentence, as the events provide the character offset and length of the pertinent characters in the text. So when a sentence is started, the OnSentence event tells you which character in the text is the start of the sentence, and also how long the sentence is.
|
Each sentence that gets spoken is italicised through the SetTextStyle helper routine (which records the position details so the sentence can be set back to non-italic when the next sentence starts). Similarly, each spoken word is highlighted using the SetTextHilite helper routine.
Note: the comment in the OnSentence event handler points out that the last OnSentence event for some text has the character position set to the last character and the length set to the negative equivalent. This gives an opportunity to reset all the text formatting back to the default styles. However it is only true if the text ends with a full stop; if not you can use the OnEndStream event for tidying up.
As an example of using speech synthesis you can make all your VCL dialogs talk to you using this small piece of code.
|
The form's OnCreate event handler sets up an OnActiveFormChange event handler for the screen object. This is triggered each time a new form is displayed, which includes VCL dialogs. Any call to ShowMessage, MessageDlg or related routines causes a TMessageForm to be displayed so the code checks for this. If the form type is found, a textual version of what's on the dialog is built up and then spoken through the SAPI Automation component.
A statement such as:
|
causes the ReadVCLDialog routine to build up and say this text:
|
Notice the full stops at the end of each line to briefly pause the speech engine at that point before moving on.
Continuous dictation is easy to set up as no specific grammar is required, but Command and Control recognition will need a grammar to educate the recogniser as to the permissible commands.
When you need SR you can either use a shared recogniser (TSpSharedRecognizer) or an in-process recogniser (TSpInprocRecognizer). The in-process recogniser is more efficient (it resides in your process address space) but means that no other SR applications can receive input from the microphone until it is closed down. On the other hand the shared recogniser can be used by multiple applications, and each one can access the microphone. It is more common to use the shared recogniser in typical SAPI applications.
The recogniser uses the notion of a recognition context to identify when it will be active (not to be confused with the use of context in a context-free grammar or CFG). A context is represented by the SpInprocRecoContext or SpSharedRecoContext interfaces. An application may use one context for each form that will use SR, or several contexts for different application modes (Office XP has a dictation mode for adding text to a document and a control mode for executing menu commands).
Recognition contexts enable you to start and stop recognition, set up the grammar and receive important recognition notifications.
Part of the process of speech recognition involves deciding what words have actually been spoken. Recognisers use a grammar to decide what has been said, where possible. SAPI 5.x represents grammars in XML.
In the case of dictation, a grammar can be used to indicate some words that are likely to be spoken. It is not feasible to try and represent the entire spoken English language as a grammar so the recogniser uses its own rules and context analysis, with any help from a grammar you might supply.
With Command and Control, the words that are understood are limited to the supported commands defined in the grammar. The grammar defines various rules that dictate what will be said and this makes the recogniser's job much easier. Rather than trying to understand anything spoken, it only needs to recognise speech that follows the supplied rules. A simple grammar that recognises three colours might look like this:
|
The GRAMMAR root node defines the language as British English ($809, American English is $409). Note that the colour rule is a top level rule and has been marked to be active by default, meaning it will be active whenever speech recognition is enabled for this context.
Grammars support lists to make implementing many similar commands easy and also support optional sections. For example this grammar will recognise any of the following:
|
You can find more details about the supported grammar syntax in the SAPI documentation
Thankfully this is quite straightforward to use. We need to set up a recognition context object for the shared recogniser so drop a TSpSharedRecContext component on the form.
Note: the recogniser will implicitly be set up if we do not create one specifically. This means you do not need to drop a TSpSharedRecognizer or a TSpInprocRecognizer on the form unless you need to use them directly.
The code below shows how you create a simple grammar that will satisfy the SR engine for continuous dictation. The grammar is represented by an ISpeechRecoGrammar interface and is used to start the dictation session. The code comes from the ContinuousDictation.dpr sample project.
|
As the SR engine does its work it calls notification methods when certain things happen, such as a phrase having been finished and recognised. These notifications are available as standard Delphi events in the Delphi Automation object component wrappers. This greatly simplifies the job of responding to the notifications.
The main event is OnRecognition, which is called when the SR engine has decided what has been spoken. Whilst working it out, it will likely call the OnHypothesis event several times. Finished phrases are added to a memo on the form and whilst a phrase is being worked out the hypotheses are added to a list box so you can see how the SR engine made its decision. Each time a new phrase is started, the hypothesis list is cleared.
You can see the list of hypotheses building up in this screenshot of the program running.
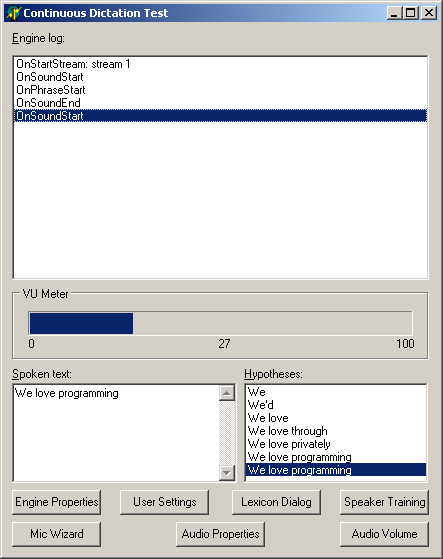
Both OnRecognition and OnHypothesis are passed a Result parameter; this is an ISpeechRecoResult results object. In Delphi 7 this is declared using the correct ISpeechRecoResult interface type, but in earlier versions this was just declared as an OleVariant (which contained the ISpeechRecoResult interface).
This code can be used in Delphi 6 and earlier to access the text that was recognised:
|
Note: this code uses late bound Automation on the results object (so no Code Completion or Code Parameters), but you could use early bound Automation with:
|
Note: the code here does not check if a valid IDispatch reference is in the Variant but probably should.
In Delphi 7 the code should look like this:
|
The buttons on the form allow various engine dialogs to be invoked (if supported). This support is all attained through a couple of methods of the recogniser object.
|
For C and C recognition we will need a grammar to give the SR engine rules by which to recognise the commands. This grammar is used by a sample project called CommandAndControl.dpr in the files that accompany this article.
|
After defining some constants the rules are laid out next. The top level rule (start, which is just an arbitrarily chosen name) is defined as the optional word colour, a value from another rule (also called colour) and the optional word please. The value from the colour rule can be identified programmatically (rather than by scanning the recognised text) thanks to it being defined as a property (chosencolour).
The colour rule defines one of three colours that can be spoken, each of which has a value defined for it. Again, this value will be accessible thanks to the list being defined as a property (colourvalue).
This grammar is stored in an XML file and loaded in the OnCreate event handler.
|
Notice that two different ISpeechRecoGrammar methods are used to instigate command and control recognition. CmdLoadFromFile loads a grammar from an XML file and CmdSetRuleIdState activates all top level rules when the first parameter is zero (you can activate individual rules by passing their rule ID).
The OnRecognition event handler does the work of locating the chosencolour property and then finding the nested colourvalue property. Its value is used to change the form colour at the user's request, for example with phrases such as:
|
This code uses a helper routine, GetPropValue whose task is to locate the appropriate property in the result object, by following the property path specified in the string array parameter. The code for GetPropValue and its own helper routine, GetProp, looks like this:
|
This is what the application looks like when running.
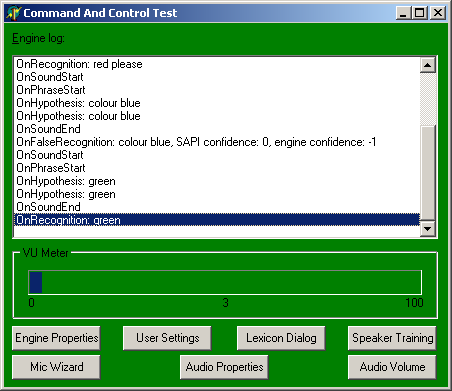
If you get issues of SR stopping (or not starting) unexpectedly, or other weird SR issues, check your recording settings have the microphone enabled.
When distributing SAPI 5.1 applications you will need get hold of the redistributable components package available as SpeechSDK51MSM.exe from http://www.microsoft.com/speech/download/SDK51 (a colossal file, weighing in at 132 Mb) contains Windows Installer merge modules for all the SAPI 5.1 components (the main DLLs, the TTS and SR engines, the Control Panel applet) and the SDK documentation includes a white paper on how to use all these components from within a Windows Installer compatible installation building tool.
Adding various speech capabilities into a Delphi application does not take an awful lot of work, particularly if you do the background work to understand the SAPI concepts.
There is much to Speech API that we have not looked at in this paper but hopefully the areas covered will be enough to whet your appetite and get you exploring further on your own.
The following is a list of useful articles and papers that I found on SAPI 5.1 development during my research on this subject.
Brian Long used to work at Borland UK, performing a number of duties including Technical Support on all the programming tools. Since leaving in 1995, Brian has spent the intervening years as a trainer, trouble-shooter and mentor focusing on the use of the C#, Delphi and C++ languages, and of the Win32 and .NET platforms. In his spare time Brian actively researches and employs strategies for the convenient identification, isolation and removal of malware. If you need training in these areas or need solutions to problems you have with them, please get in touch or visit Brian's Web site.
Brian authored a Borland Pascal problem-solving book in 1994 and occasionally acts as a Technical Editor for Wiley (previously Sybex); he was the Technical Editor for Mastering Delphi 7 and Mastering Delphi 2005 and also contributed a chapter to Delphi for .NET Developer Guide. Brian is a regular columnist in The Delphi Magazine and has had numerous articles published in Developer's Review, Computing, Delphi Developer's Journal and EXE Magazine. He was nominated for the Spirit of Delphi award in 2000.
Go to the speech capabilities overview
Go to the SAPI 4 High Level Interfaces
article
Go to the SAPI 4 Low Level Interfaces
article
Go back to the top of this SAPI 5.1 article